
AWS EMRでImpalaを試す!起動〜クエリ実行まで
今回はAmazon Elastic MapReduce(EMR)でImpalaを試してみます。
EMRというのはAmazonのサービスの1つでHadoop環境を提供しまっせ、的なサービスです。
ImpalaはClouderaが開発しているHadoop環境用のSQLクエリエンジン的な物です。
全体の流れ
- AWSコンソールからEMRのクラスタ構築・起動
- ログイン、テストデータのロード
- Impalaでクエリ発行
EMRはデフォルトでImpalaをサポートしていますので、Impalaのインストールなどは不要です。
個人的にHadoop構築はかなり面倒な部類の作業なので、そこが自動化されつつさらにImpalaインストールも不要というのは大きいですね。どうせならPrestoとかもデフォで提供してよ!って感じですが。
EMRの起動
まずは環境構築から。
コンソール画面からElastic MapReduceを選択します。
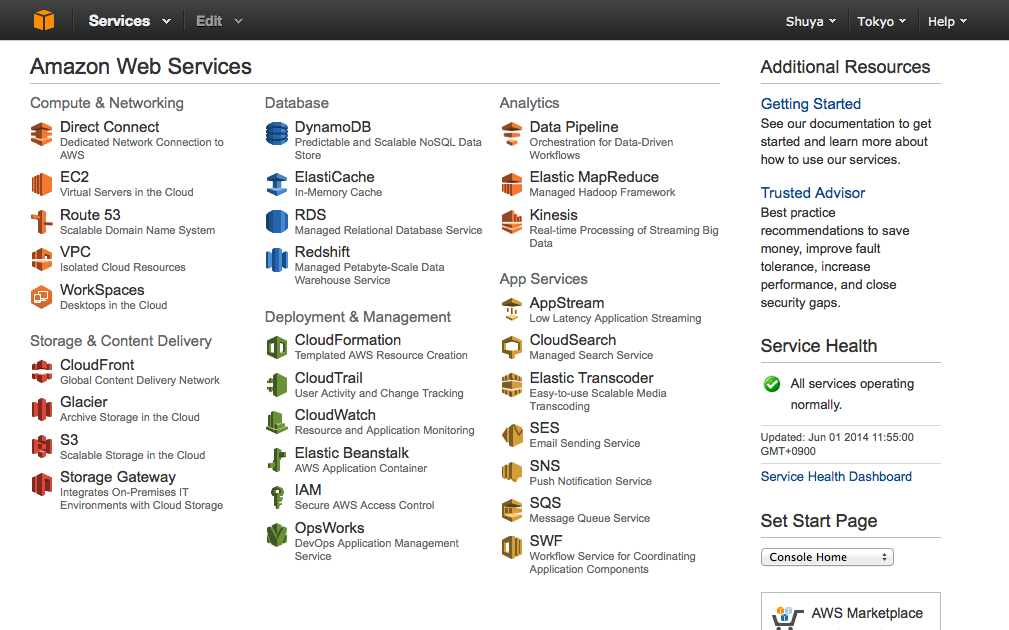
以下のように適当に入力していきます。
Log出力先のS3バケットは予め作っておきました。
AMIはHadoop 2.x以上のものを選択します。ここでは最新バージョンを選択しました。
すると下のAdditional applicationsでimpalaが選択できるので選択しておきます。impalaを選択した後でちゃんとConfigure and addを押してimpalaをaddしておきます。初めこれを忘れて「Impalaインストールされてねーじゃん!」となりました。。。

クラスタの各インスタンス数などはデフォルトで。

m1.mediumが合計3つです。2014/6/1(日)現在の東京リージョンの料金はEC2代金0.122ドル+EMR代金0.022ドルなので1時間0.144ドルです。これが3台分なので、1時間約43円というところです。試してみる程度ならそれほど痛くない料金かと思います。
ちなみにHadoop 2.x系を選択するとm1.smallは選択できなくなります。
EC2 key pairは予め他のEC2のときに作成していたものをそのまま流用しました。
こんな感じで設定してクラスタを作成すると管理画面に移動します。

状態がStartingなのでクラスタ作成中です。大体3分ほどでRunningになり、起動完了です。
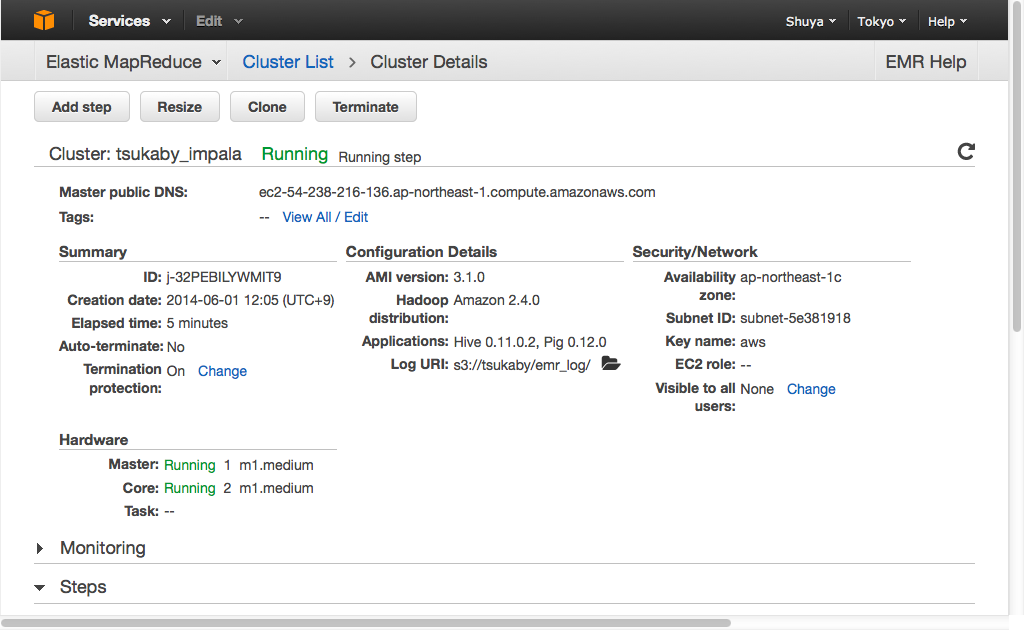
マスタノードログイン
次はマスターノードにログインします。
~/.ssh/configに以下の設定を追加してSSH接続できるようにします。
Host aws_impala
User hadoop
port 22
Hostname ec2-54-238-216-136.ap-northeast-1.compute.amazonaws.com
IdentityFile ~/.ssh/aws.pem
IdentitiesOnly yes
Host名のところはお好きにどうぞ。Userはhadoopです。HostnameはEMR管理画面上に出たMaster public DNSの値を入れます。IdentityFileの値はEC2管理画面などで作成しDLしておいたpemファイルのパスを指定します。
初めUserをec2-userにしたままログインしてしまったため、「あれ!?hadoopコマンドないんですけど!!」となって混乱しました。
上記の設定をするとssh aws_impalaコマンドで入れます。
[tsukaby@tsukamac tsukaby]% ssh aws_impala
Last login: Sun Jun 1 04:41:57 2014 from p57d506.tokynt01.ap.so-net.ne.jp
__| __|_ )
_| ( / Amazon Linux AMI
___|\___|___|
https://aws.amazon.com/amazon-linux-ami/2014.03-release-notes/
9 package(s) needed for security, out of 19 available
Run "sudo yum update" to apply all updates.
--------------------------------------------------------------------------------
Welcome to Amazon Elastic MapReduce running Hadoop and Amazon Linux.
Hadoop is installed in /home/hadoop. Log files are in /mnt/var/log/hadoop. Check
/mnt/var/log/hadoop/steps for diagnosing step failures.
The Hadoop UI can be accessed via the following commands:
ResourceManager lynx http://localhost:9026/
NameNode lynx http://localhost:9101/
--------------------------------------------------------------------------------
[hadoop@ip-172-31-7-222 ~]$
やりました!
これで入れない人はpemのパーミッション設定やクラスタ作成時のkey指定部分を確認しましょう。
初回はsudo yum updateしておきましょう。
sudo yum update
テストデータ作成
テストデータはAmazonが用意してくれているのでそれを使います。
このページを参考にしてログインしたマスターノード上でjavaプログラムを実行するとテストデータが作成されます。
こんな感じで完了します。
[hadoop@ip-172-31-7-222 ~]$ mkdir test
[hadoop@ip-172-31-7-222 ~]$ cd test
[hadoop@ip-172-31-7-222 test]$ wget http://elasticmapreduce.s3.amazonaws.com/samples/impala/dbgen-1.0-jar-with-dependencies.jar
--2014-06-01 04:45:47-- http://elasticmapreduce.s3.amazonaws.com/samples/impala/dbgen-1.0-jar-with-dependencies.jar
elasticmapreduce.s3.amazonaws.com (elasticmapreduce.s3.amazonaws.com) をDNSに問いあわせています... 207.171.189.81
elasticmapreduce.s3.amazonaws.com (elasticmapreduce.s3.amazonaws.com)|207.171.189.81|:80 に接続しています... 接続しました。
HTTP による接続要求を送信しました、応答を待っています... 200 OK
長さ: 3129700 (3.0M) [application/x-java-archive]
`dbgen-1.0-jar-with-dependencies.jar' に保存中
100%[==========================================================>] 3,129,700 1.46MB/s 時間 2.0s
2014-06-01 04:45:49 (1.46 MB/s) - `dbgen-1.0-jar-with-dependencies.jar' へ保存完了 [3129700/3129700]
[hadoop@ip-172-31-7-222 test]$ java -cp dbgen-1.0-jar-with-dependencies.jar DBGen -p /tmp/dbgen -b 1 -c 1 -t 1
2014-06-01 04:46:12 [ INFO ] Books table size = 1 GB
2014-06-01 04:46:12 [ INFO ] Books table partitioned = false
2014-06-01 04:46:12 [ INFO ] Customers table size = 1 GB
2014-06-01 04:46:12 [ INFO ] Customers table partitioned = false
2014-06-01 04:46:12 [ INFO ] Transactions table size = 1 GB
2014-06-01 04:46:12 [ INFO ] Transactions table partitioned = false
2014-06-01 04:46:12 [ INFO ] Base path = /tmp/dbgen
2014-06-01 04:46:12 [ INFO ] Generating table: books
2014-06-01 04:46:12 [ INFO ] 0%
2014-06-01 04:46:17 [ INFO ] 5%
2014-06-01 04:46:20 [ INFO ] 10%
2014-06-01 04:46:23 [ INFO ] 15%
2014-06-01 04:46:27 [ INFO ] 20%
2014-06-01 04:46:30 [ INFO ] 25%
2014-06-01 04:46:34 [ INFO ] 30%
2014-06-01 04:46:37 [ INFO ] 35%
2014-06-01 04:46:40 [ INFO ] 40%
2014-06-01 04:46:43 [ INFO ] 45%
2014-06-01 04:46:47 [ INFO ] 50%
2014-06-01 04:46:50 [ INFO ] 55%
2014-06-01 04:46:54 [ INFO ] 60%
2014-06-01 04:46:57 [ INFO ] 65%
2014-06-01 04:47:00 [ INFO ] 70%
2014-06-01 04:47:03 [ INFO ] 75%
2014-06-01 04:47:07 [ INFO ] 80%
2014-06-01 04:47:10 [ INFO ] 85%
2014-06-01 04:47:13 [ INFO ] 90%
2014-06-01 04:47:16 [ INFO ] 95%
2014-06-01 04:47:20 [ INFO ] 100%
2014-06-01 04:47:20 [ INFO ] Generating table: customers
2014-06-01 04:47:20 [ INFO ] 0%
2014-06-01 04:47:25 [ INFO ] 5%
2014-06-01 04:47:28 [ INFO ] 10%
2014-06-01 04:47:32 [ INFO ] 15%
2014-06-01 04:47:35 [ INFO ] 20%
2014-06-01 04:47:39 [ INFO ] 25%
2014-06-01 04:47:42 [ INFO ] 30%
2014-06-01 04:47:46 [ INFO ] 35%
2014-06-01 04:47:49 [ INFO ] 40%
2014-06-01 04:47:53 [ INFO ] 45%
2014-06-01 04:47:57 [ INFO ] 50%
2014-06-01 04:48:00 [ INFO ] 55%
2014-06-01 04:48:04 [ INFO ] 60%
2014-06-01 04:48:07 [ INFO ] 65%
2014-06-01 04:48:10 [ INFO ] 70%
2014-06-01 04:48:14 [ INFO ] 75%
2014-06-01 04:48:17 [ INFO ] 80%
2014-06-01 04:48:21 [ INFO ] 85%
2014-06-01 04:48:24 [ INFO ] 90%
2014-06-01 04:48:28 [ INFO ] 95%
2014-06-01 04:48:31 [ INFO ] 100%
2014-06-01 04:48:31 [ INFO ] Generating table: transactions
2014-06-01 04:48:31 [ INFO ] 0%
2014-06-01 04:48:36 [ INFO ] 5%
2014-06-01 04:48:40 [ INFO ] 10%
2014-06-01 04:48:44 [ INFO ] 15%
2014-06-01 04:48:48 [ INFO ] 20%
2014-06-01 04:48:52 [ INFO ] 25%
2014-06-01 04:48:57 [ INFO ] 30%
2014-06-01 04:49:01 [ INFO ] 35%
2014-06-01 04:49:05 [ INFO ] 40%
2014-06-01 04:49:09 [ INFO ] 45%
2014-06-01 04:49:13 [ INFO ] 50%
2014-06-01 04:49:17 [ INFO ] 55%
2014-06-01 04:49:21 [ INFO ] 60%
2014-06-01 04:49:25 [ INFO ] 65%
2014-06-01 04:49:29 [ INFO ] 70%
2014-06-01 04:49:33 [ INFO ] 75%
2014-06-01 04:49:37 [ INFO ] 80%
2014-06-01 04:49:41 [ INFO ] 85%
2014-06-01 04:49:45 [ INFO ] 90%
2014-06-01 04:49:49 [ INFO ] 95%
2014-06-01 04:49:53 [ INFO ] 100%
2014-06-01 04:49:54 [ INFO ] Total Time: 221 seconds
[hadoop@ip-172-31-7-222 test]$ hadoop fs -mkdir /data/
[hadoop@ip-172-31-7-222 test]$ hadoop fs -put /tmp/dbgen/* /data/
[hadoop@ip-172-31-7-222 test]$ hadoop fs -ls -h -R /data/
drwxr-xr-x - hadoop supergroup 0 2014-06-01 04:50 /data/books
-rw-r--r-- 1 hadoop supergroup 1.0 G 2014-06-01 04:50 /data/books/books
drwxr-xr-x - hadoop supergroup 0 2014-06-01 04:50 /data/customers
-rw-r--r-- 1 hadoop supergroup 1.0 G 2014-06-01 04:50 /data/customers/customers
drwxr-xr-x - hadoop supergroup 0 2014-06-01 04:51 /data/transactions
-rw-r--r-- 1 hadoop supergroup 1.0 G 2014-06-01 04:51 /data/transactions/transactions
[hadoop@ip-172-31-7-222 test]$
ここまででHDFS上に合計3GBのテストデータを作成することができました。
次はImpala用のテーブルを作成します。
こちらも同様にAmazonのこのページを参考にしてテーブルを作成します。以下のような感じで完了します。
[hadoop@ip-172-31-7-222 test]$ cd
[hadoop@ip-172-31-7-222 ~]$ impala-shell
Starting Impala Shell without Kerberos authentication
Connected to ip-172-31-7-222.ap-northeast-1.compute.internal:21000
Server version: impalad version 1.2.4 RELEASE (build df140da35e1789e305b85a3d1fb63914fd15d163)
Welcome to the Impala shell. Press TAB twice to see a list of available commands.
Copyright (c) 2012 Cloudera, Inc. All rights reserved.
(Shell build version: Impala Shell v1.2.4 (df140da) built on Fri May 9 15:06:06 PDT 2014)
[ip-172-31-7-222.ap-northeast-1.compute.internal:21000] > create EXTERNAL TABLE books( id BIGINT, isbn STRING, category STRING, publish_date TIMESTAMP, publisher STRING, price FLOAT )
> ROW FORMAT DELIMITED FIELDS TERMINATED BY '|' LOCATION '/data/books/';
Query: create EXTERNAL TABLE books( id BIGINT, isbn STRING, category STRING, publish_date TIMESTAMP, publisher STRING, price FLOAT ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '|' LOCATION '/data/books/'
Returned 0 row(s) in 3.22s
[ip-172-31-7-222.ap-northeast-1.compute.internal:21000] > create EXTERNAL TABLE customers( id BIGINT, name STRING, date_of_birth TIMESTAMP, gender STRING, state STRING, email STRING, phone STRING )
> ROW FORMAT DELIMITED FIELDS TERMINATED BY '|' LOCATION '/data/customers/';
Query: create EXTERNAL TABLE customers( id BIGINT, name STRING, date_of_birth TIMESTAMP, gender STRING, state STRING, email STRING, phone STRING ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '|' LOCATION '/data/customers/'
Returned 0 row(s) in 1.12s
[ip-172-31-7-222.ap-northeast-1.compute.internal:21000] > create EXTERNAL TABLE transactions( id BIGINT, customer_id BIGINT, book_id BIGINT, quantity INT, transaction_date TIMESTAMP )
> ROW FORMAT DELIMITED FIELDS TERMINATED BY '|' LOCATION '/data/transactions/';
Query: create EXTERNAL TABLE transactions( id BIGINT, customer_id BIGINT, book_id BIGINT, quantity INT, transaction_date TIMESTAMP ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '|' LOCATION '/data/transactions/'
Returned 0 row(s) in 1.15s
[ip-172-31-7-222.ap-northeast-1.compute.internal:21000] >
どのファイル(テーブル)も1GBあるのに数秒でロード完了していますね。早い。
クエリ実行
ココまで来たら後はSQLなので、多少の違いはあれどいつも通り、という感じですね。
例によってAmazonの公式を参考にしながらクエリ実行します。(impala-shell上から実行します。)
クエリ1つめ。
SELECT COUNT(*)
FROM customers
WHERE name = 'Harrison SMITH';
Query: select COUNT(*) FROM customers WHERE name = 'Harrison SMITH'
+----------+
| count(*) |
+----------+
| 347 |
+----------+
Returned 1 row(s) in 10.69s
クエリ2つめ。
SELECT category, count(*) cnt
FROM books
GROUP BY category
ORDER BY cnt DESC LIMIT 10;
Query: select category, count(*) cnt FROM books GROUP BY category ORDER BY cnt DESC LIMIT 10
+-------------------------+--------+
| category | cnt |
+-------------------------+--------+
| BIOGRAPHY-AUTOBIOGRAPHY | 314294 |
| HOUSE-HOME | 314127 |
| DESIGN | 314014 |
| FAMILY-RELATIONSHIPS | 314009 |
| ART | 313996 |
| PHILOSOPHY | 313994 |
| RELIGION | 313888 |
| TECHNOLOGY-ENGINEERING | 313878 |
| NATURE | 313867 |
| PETS | 313767 |
+-------------------------+--------+
Returned 10 row(s) in 9.16s
クエリ3つめ。
SELECT tmp.book_category, ROUND(tmp.revenue, 2) AS revenue
FROM (
SELECT books.category AS book_category, SUM(books.price * transactions.quantity) AS revenue
FROM books JOIN [SHUFFLE] transactions ON (
transactions.book_id = books.id
AND YEAR(transactions.transaction_date) BETWEEN 2008 AND 2010
)
GROUP BY books.category
) tmp
ORDER BY revenue DESC LIMIT 10;
Query: select tmp.book_category, ROUND(tmp.revenue, 2) AS revenue FROM ( SELECT books.category AS book_category, SUM(books.price * transactions.quantity) AS revenue FROM books JOIN [SHUFFLE] transactions ON ( transactions.book_id = books.id AND YEAR(transactions.transaction_date) BETWEEN 2008 AND 2010 ) GROUP BY books.category ) tmp ORDER BY revenue DESC LIMIT 10
+------------------------+--------------+
| book_category | revenue |
+------------------------+--------------+
| DESIGN | 240352255.70 |
| ART | 239000884.25 |
| FICTION | 237711958.06 |
| ARCHITECTURE | 237645647.96 |
| TECHNOLOGY-ENGINEERING | 237536983.00 |
| PHILOSOPHY | 237424896.78 |
| FOREIGN-LANGUAGE-STUDY | 237163185.93 |
| GARDENING | 237157577.12 |
| JUVENILE-FICTION | 237142742.57 |
| PHOTOGRAPHY | 237057002.42 |
+------------------------+--------------+
Returned 10 row(s) in 33.73s
クエリ4つめ。
SELECT tmp.book_category, ROUND(tmp.revenue, 2) AS revenue
FROM (
SELECT books.category AS book_category, SUM(books.price * transactions.quantity) AS revenue
FROM books
JOIN [SHUFFLE] transactions ON (
transactions.book_id = books.id
)
JOIN [SHUFFLE] customers ON (
transactions.customer_id = customers.id
AND customers.state IN ('WA', 'CA', 'NY')
)
GROUP BY books.category
) tmp
ORDER BY revenue DESC LIMIT 10;
Query: select tmp.book_category, ROUND(tmp.revenue, 2) AS revenue FROM ( SELECT books.category AS book_category, SUM(books.price * transactions.quantity) AS revenue FROM books JOIN [SHUFFLE] transactions ON ( transactions.book_id = books.id ) JOIN [SHUFFLE] customers ON ( transactions.customer_id = customers.id AND customers.state IN ('WA', 'CA', 'NY') ) GROUP BY books.category ) tmp ORDER BY revenue DESC LIMIT 10
+---------------------+-------------+
| book_category | revenue |
+---------------------+-------------+
| TRANSPORTATION | 69682017.00 |
| LAW | 69395756.09 |
| BODY-MIND-SPIRIT | 69303241.30 |
| JUVENILE-NONFICTION | 69066659.74 |
| GARDENING | 69024761.73 |
| COOKING | 69022776.17 |
| DESIGN | 68791425.02 |
| HUMOR | 68790930.23 |
| PSYCHOLOGY | 68732412.29 |
| NATURE | 68697616.05 |
+---------------------+-------------+
Returned 10 row(s) in 79.01s
m1.mediumインスタンスでこれはかなり早いです!Impalaすごい・・・。
[visualizer id=“592”]
ClouderaのCDH5やCDH4+Impala(別途インストール)でも結局impala-shellから上記コマンドを実行するので、差はありません。個人的にはCDHを使ってもHadoop個別でセットアップしても設定部分が面倒なので、EMR凄くいい感じでした。
みなさんもImpalaやりたいときはEMRを使ってみてはいかがでしょうか。
※最後に忘れずにEMRクラスタをTerminateしましょう。