
AWS RDS(MySQL)とImpalaを比較!同一テストデータで検証してみる
前回の投稿でAWS EMR上でImpalaを動作させてみました。
動作させてみたのは良いのですが、本当に早いのかイマイチ分かりません。
そこで同一のテストデータをAWS RDS(MySQL)に投入して、そちらで何秒かかるのか計測してみたいと思います。
結論としてはクエリによりけりですが、5倍〜30倍、Impalaの方が早いです。
RDS環境構築
まずはRDSを用意します。
MySQLを選択。

今回は検証なので、障害とか考えなくてよい為、Multi AZなどはOFFにします。
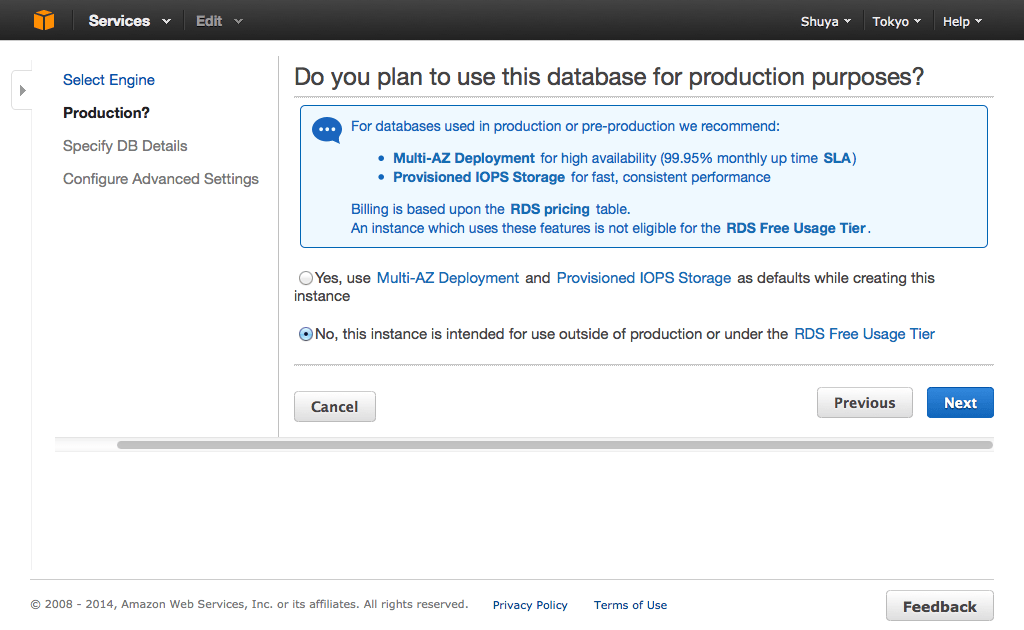
以下のように設定します。
インスタンスは1台あたりの料金がImpalaのときと同じくらいの料金であるdb.m3.mediumを選択します。1時間10円ほどです。(もっともEMR+Impalaでやったときはインスタンスは合計3台だったので、この時点で不公平ではあるのですが。とりあえず先へ進みます。)
DBは初め5GBで作って足りてましたが、後でALTER TABLEするときに足りなくなりました。10GBくらいはあった方が良いです。
本当はProvisioned IOPSは使った方が早いのですが、とりあえず今回はOFFで。
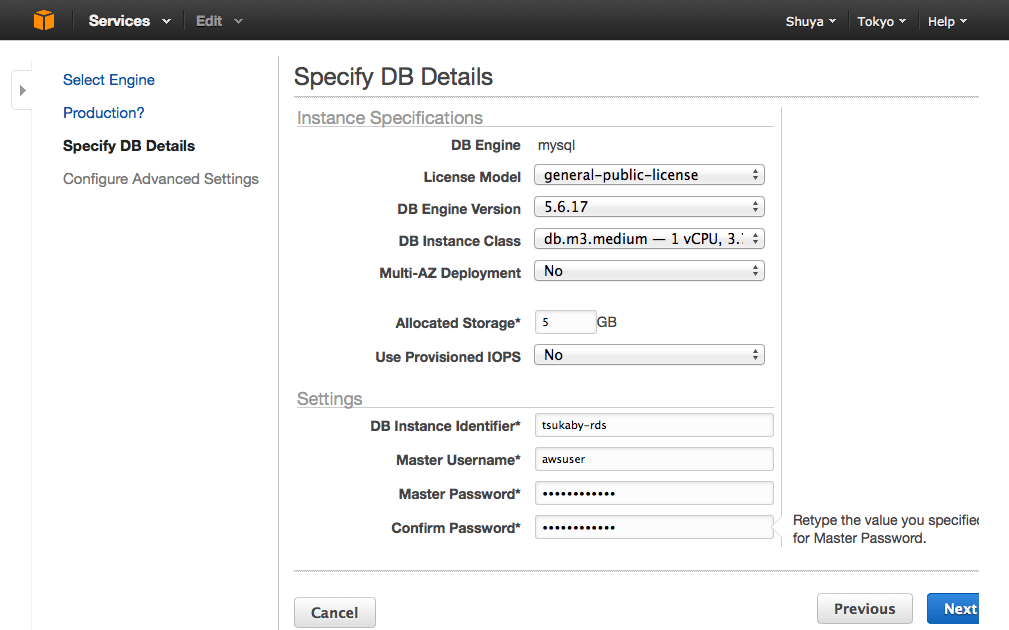
この辺りは適当に。
選択したVPC SecurityによってはMySQLのポート3306が閉じられているため、後で管理画面から確認しておきます。閉じられていたら空けておきます。
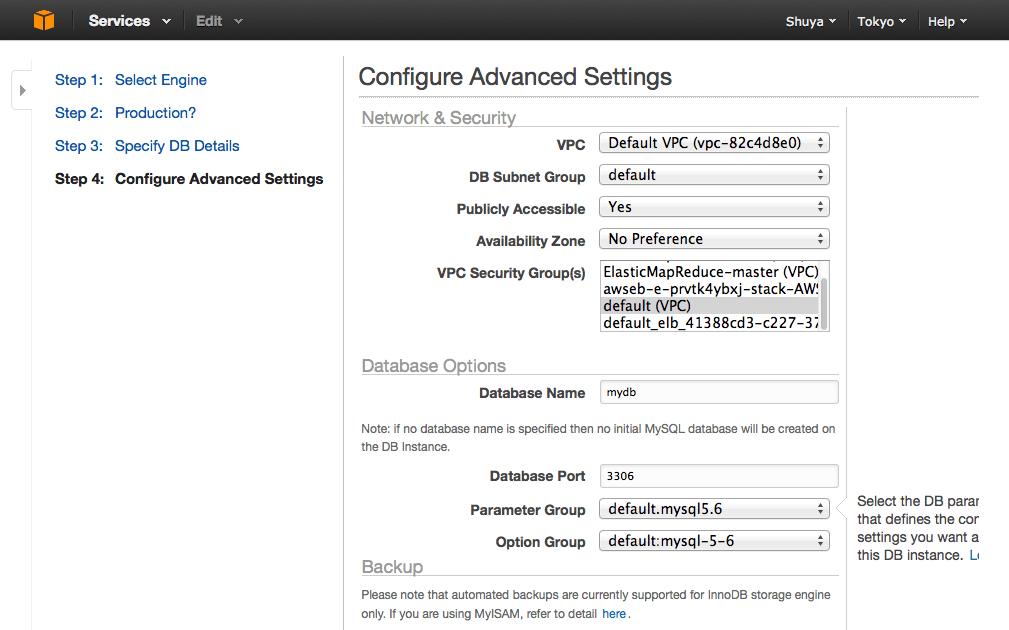
Backupは不要なので0にします。
これでLaunch DBして作成開始です。
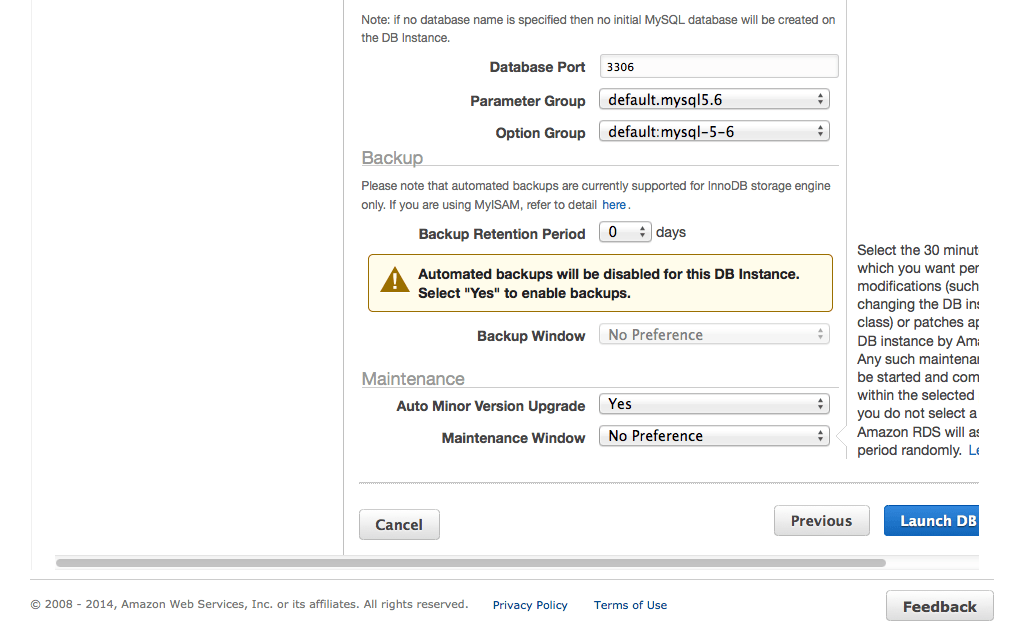
結構かかります。5分ほど待ちます。
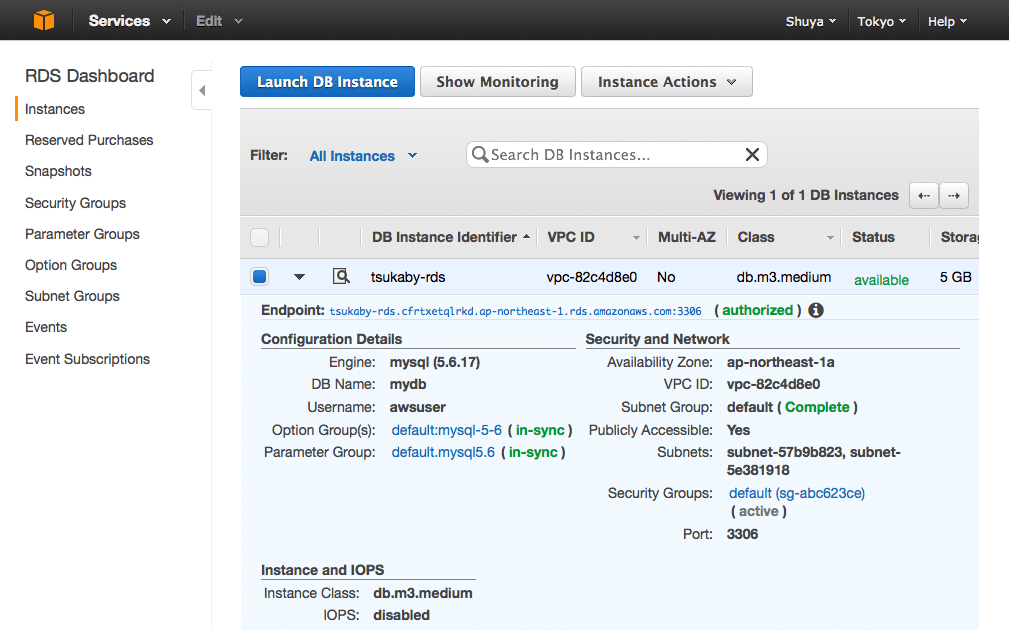
最終的に以下のようにavailableになると完了です。
テストデータ作成
RDSは残念ながら直接SSH接続することはできません。そのため、テストデータは一旦ローカル(Mac)に作成してからLOAD DATA LOCAL INFILEコマンドで取り込むことにします。合計3GBあるのでかなりきついですが。。。この辺りもっと上手い方法あれば教えてください。
まずはImpalaのときと同じようにテストデータを用意します。
mkdir test
cd test
wget http://elasticmapreduce.s3.amazonaws.com/samples/impala/dbgen-1.0-jar-with-dependencies.jar
# 今回は./配下に作成しました
java -cp dbgen-1.0-jar-with-dependencies.jar DBGen -p ./dbgen -b 1 -c 1 -t 1
これで前回同様booksファイルなどができました。
次はいよいよMySQLの方で操作をしていきます。
まずはログインします。RDS管理画面上のEndpointという部分にホスト名が載っているのでこれを使って以下のように接続します。
ホスト名、ユーザ名は各自変えます。パスワードは管理画面で先ほど登録したものです。
mysql -h tsukaby-rds.cfrtxetqlrkd.ap-northeast-1.rds.amazonaws.com -P 3306 -u awsuser -p
(中略)
# いつものコンソールが出ます
mysql>
次はテーブルを作成します。Impalaの例の方だとisbnなどはSTRING型なのですが、MySQLには無いのでVARCHARにしました。
# RDS管理画面上で入力したDB名
use mydb
create TABLE books(
id BIGINT,
isbn VARCHAR(128),
category VARCHAR(128),
publish_date TIMESTAMP,
publisher VARCHAR(128),
price FLOAT
);
create TABLE customers(
id BIGINT,
name VARCHAR(128),
date_of_birth TIMESTAMP,
gender VARCHAR(128),
state VARCHAR(128),
email VARCHAR(256),
phone VARCHAR(128)
);
create TABLE transactions(
id BIGINT,
customer_id BIGINT,
book_id BIGINT,
quantity INT,
transaction_date TIMESTAMP
);
確認です。
mysql> show tables;
+----------------+
| Tables_in_mydb |
+----------------+
| books |
| customers |
| transactions |
+----------------+
3 rows in set (0.01 sec)
作成できたので次はテストデータを投入します。books, customers, transactionsファイルのパスは各自変えます。自分の場合は以下のような感じです。
load data local infile '/Users/tsukaby/test/dbgen/books/books'
into table books
fields terminated by '|';
load data local infile '/Users/tsukaby/test/dbgen/customers/customers'
into table customers
fields terminated by '|';
load data local infile '/Users/tsukaby/test/dbgen/transactions/transactions'
into table transactions
fields terminated by '|';
やはりここが長いです。バルクインポートとは言え、合計3GBのデータをネットワーク越しに投入しているのでそりゃ時間かかりますね。同一LANのEC2上から上記コマンド実行した方が圧倒的に早いと思います。
ここでいくつかwarningが発生します。これはテストデータの中に1970-01-01というデータがあるためです。MySQLのTIMESTAMP型が許可する値は1970-01-01 00:00:01〜ですが、上記のテストデータをインポートしようとすると1970-01-01が1970-01-01 00:00:00に変換され、範囲を超えちゃっているため発生しています。一部のデータが0000-00-00 00:00:00になってますが、まあ問題ない件数なので無視します。
3つのデータが無事入ったので、いよいよSQLを実行してみます。(ちなみにうちは光回線ですが20分かかりました)
クエリ実行
ではいよいよImpalaの方と同じクエリを発行してみたいと思います。ちなみに検索結果が違うのは上記のWarningのせいです。
クエリ1つめ。
SELECT COUNT(*)
FROM customers
WHERE name='Harrison SMITH';
mysql> SELECT COUNT(*)
-> FROM customers
-> WHERE name='Harrison SMITH';
+----------+
| COUNT(*) |
+----------+
| 323 |
+----------+
1 row in set (41.54 sec)
クエリ2つめ。
SELECT category, count(*) cnt
FROM books
GROUP BY category
ORDER BY cnt DESC LIMIT 10;
mysql> SELECT category, count(*) cnt
-> FROM books
-> GROUP BY category
-> ORDER BY cnt DESC LIMIT 10;
+-------------------------+--------+
| category | cnt |
+-------------------------+--------+
| GAMES | 314906 |
| BIBLES | 314792 |
| HOUSE-HOME | 314251 |
| BIOGRAPHY-AUTOBIOGRAPHY | 314089 |
| HEALTH-FITNESS | 313944 |
| LAW | 313899 |
| DESIGN | 313820 |
| TRANSPORTATION | 313766 |
| MATHEMATICS | 313756 |
| PERFORMING-ARTS | 313712 |
+-------------------------+--------+
10 rows in set (1 min 2.70 sec)
クエリ3つめ。[SHUFFLE]は指定できない為、外しました。
SELECT tmp.book_category, ROUND(tmp.revenue, 2) AS revenue
FROM (
SELECT books.category AS book_category, SUM(books.price * transactions.quantity) AS revenue
FROM books JOIN transactions ON (
transactions.book_id = books.id
AND YEAR(transactions.transaction_date) BETWEEN 2008 AND 2010
)
GROUP BY books.category
) tmp
ORDER BY revenue DESC LIMIT 10;
# 処理が帰ってきませんでした(30min以上かかります)
クエリ4つめ。[SHUFFLE]は指定できない為、外しました。
SELECT tmp.book_category, ROUND(tmp.revenue, 2) AS revenue
FROM (
SELECT books.category AS book_category, SUM(books.price * transactions.quantity) AS revenue
FROM books
JOIN transactions ON (
transactions.book_id = books.id
)
JOIN customers ON (
transactions.customer_id = customers.id
AND customers.state IN ('WA', 'CA', 'NY')
)
GROUP BY books.category
) tmp
ORDER BY revenue DESC LIMIT 10;
# 処理帰ってこない可能性大なので試してません
こんな感じになりました。
クエリ1と2しか計測できてませんが、MySQLよりImpalaの方が5倍以上高速ですね。クエリ3と4については、そもそもMySQLだと絶望的なので、Impalaが何倍高速なのか分かりません。分かりませんが、クエリ3は30分以上待っても結果が帰らないことから、少なくともImpalaの方が60倍以上高速であることが分かります。
クエリ実行(インデックスありバージョン)
上記のテーブルはインデックスがありません。そのため全体的に損しています。折角なのでインデックスを作成して同様のクエリを投げてみたいと思います。
インデックスを作成する前にRDSのストレージサイズを5GBから10GBに変更しておきます。ALTER TABLEでテーブルコピーが発生しますが、このとき空きが足りなくなる為です。(ERROR 1114 (HY000): The table ‘#sql-2895_6’ is fullというようなエラーが出ます。)
次にインデックスを作成します。
ALTER TABLE books ADD PRIMARY KEY (id), ADD INDEX idx_category (category);
ALTER TABLE customers ADD PRIMARY KEY (id), ADD INDEX idx_name (name);
SET FOREIGN_KEY_CHECKS = 0;
ALTER TABLE transactions ADD PRIMARY KEY (id), ADD FOREIGN KEY (book_id) references books(id), ADD FOREIGN KEY (customer_id) references customers(id);
SET FOREIGN_KEY_CHECKS = 1;
3つ目のALTERは外部キー設定があって、処理時間がやばいことになるので一旦チェック処理を外しています。チェック処理ありだと数時間かかるかと思います。
これだけでも合計1時間近くかかりました。
ではクエリを実行してみます。
クエリ1つめ。
SELECT COUNT(*)
FROM customers
WHERE name='Harrison SMITH';
mysql> SELECT COUNT(*)
-> FROM customers
-> WHERE name='Harrison SMITH';
+----------+
| COUNT(*) |
+----------+
| 323 |
+----------+
1 row in set (0.13 sec)
クエリ2つめ。
SELECT category, count(*) cnt
FROM books
GROUP BY category
ORDER BY cnt DESC LIMIT 10;
mysql> SELECT category, count(*) cnt
-> FROM books
-> GROUP BY category
-> ORDER BY cnt DESC LIMIT 10;
+-------------------------+--------+
| category | cnt |
+-------------------------+--------+
| GAMES | 314906 |
| BIBLES | 314792 |
| HOUSE-HOME | 314251 |
| BIOGRAPHY-AUTOBIOGRAPHY | 314089 |
| HEALTH-FITNESS | 313944 |
| LAW | 313899 |
| DESIGN | 313820 |
| TRANSPORTATION | 313766 |
| MATHEMATICS | 313756 |
| PERFORMING-ARTS | 313712 |
+-------------------------+--------+
10 rows in set (41.37 sec)
クエリ3つめ。
SELECT tmp.book_category, ROUND(tmp.revenue, 2) AS revenue
FROM (
SELECT books.category AS book_category, SUM(books.price * transactions.quantity) AS revenue
FROM books JOIN transactions ON (
transactions.book_id = books.id
AND YEAR(transactions.transaction_date) BETWEEN 2008 AND 2010
)
GROUP BY books.category
) tmp
ORDER BY revenue DESC LIMIT 10;
mysql> SELECT tmp.book_category, ROUND(tmp.revenue, 2) AS revenue
-> FROM (
-> SELECT books.category AS book_category, SUM(books.price * transactions.quantity) AS revenue
-> FROM books JOIN transactions ON (
-> transactions.book_id = books.id
-> AND YEAR(transactions.transaction_date) BETWEEN 2008 AND 2010
-> )
-> GROUP BY books.category
-> ) tmp
-> ORDER BY revenue DESC LIMIT 10;
+-------------------+--------------+
| book_category | revenue |
+-------------------+--------------+
| GAMES | 238743332.97 |
| POETRY | 238661918.78 |
| ARCHITECTURE | 238393772.00 |
| SPORTS-RECREATION | 237673101.64 |
| TRAVEL | 237228872.71 |
| TRANSPORTATION | 237157773.75 |
| HUMOR | 237005005.93 |
| FICTION | 236990014.52 |
| SELF-HELP | 236977225.61 |
| STUDY-AIDS | 236974428.05 |
+-------------------+--------------+
10 rows in set (20 min 29.77 sec)
クエリ4つめ。
SELECT tmp.book_category, ROUND(tmp.revenue, 2) AS revenue
FROM (
SELECT books.category AS book_category, SUM(books.price * transactions.quantity) AS revenue
FROM books
JOIN transactions ON (
transactions.book_id = books.id
)
JOIN customers ON (
transactions.customer_id = customers.id
AND customers.state IN ('WA', 'CA', 'NY')
)
GROUP BY books.category
) tmp
ORDER BY revenue DESC LIMIT 10;
# 処理帰ってきませんでした。
インデックスのおかげで早くなってます。
クエリ1は圧倒的に早いですね。B木の一部分だけ取ってきて、そこをcountすればいいだけなので当然早くなります。
クエリ2は若干早くなっています。whereが無いので結局全レコード調べなくちゃならないので遅いですね。
クエリ3は結果が帰ってきたことに驚きました。自分の知識ではなんで早くなったか分かりませんが。結合部分のインデックスで結合対象絞れるし、group by のcategoryでもサマる対象の部分木がすぐ取れるからでしょうか。結局これもクエリ1のように処理対象大きく削れる訳じゃないので遅いですが。
クエリ4はやっぱり遅いですね。これだけGROUP BYとJOINしてれば当然ですね。
まとめ
という訳でImpalaめっちゃ早いです!group byはRDBMSでは限界ありますね。
簡単に処理時間をグラフ化してみました。一部数値出てないので完璧なグラフじゃありませんが。
[visualizer id=“585”]
Impala早いですね。
きっちりした検証ではありませんが、Impala早いという感触を得ることができました。